What is DBMS
What does mean of Data
Facts or ideas recorded onto some media suitable for future processing......
Database
a collection of related data that are given a relational or structural foundation for efficient storage and control, authorized and easy accessibility, purposive searching and retrieval, convenient use and transmission of the data.
DBMS
a collection of interrelated data and a set of programs that provides a data management environment for efficient storage and control, authorized and easy accessibility, purposive searching and retrieval, convenient use and transmission of the data.
Need for DBMS?
Integrated data specification: DBMS reduces data isolation in different files and different formats and develop integrated data specification.
Security: Design and implementation of data security is an important aspect of DBMS.
Program-data independence: The separation of data descriptions (metadata) from the application programs that use the data is called data independence. With the database approach, data descriptions are stored in a central location called the repository. This property of database systems allows an organization's data to change and evolve (within limits) without changing the application programs that process the data.
Minimal data redundancy: In traditional file processing system data redundancy occurs due different language, format, and time of file creation. The design goal with the database approach is that previously separate (and redundant) data files are integrated into a single, logical structure. Each primary fact is recorded (ideally) in only one place in the database. However, the database approach does not eliminate redundancy entirely, but it allows the designer to carefully control the type and amount of redundancy.
Improved data consistency: By eliminating (or controlling) data redundancy, we greatly reduce the opportunities for inconsistency. DBMS ensure data integrity through consistency constraints, validation etc.
Improved data sharing: A database is designed as a shared corporate resource. Authorized users are granted permission to use the database, and each user (or group of users) is provided one or more user views to facilitate this use.
Increased productivity of application development: The database management system provides a number of high-level productivity tools such as forms and report generators and high-level languages that automate some of the activities of database design and implementation.
Enforcement of standards: The DBA always enforces data standards during design, implementation and application of database. These standards will include naming conventions, data quality standards, and uniform procedures for accessing, updating, and protecting data.
Improved data accessibility and responsiveness: DBMS provides favorable environment in easy access and retrieve required data in convenient and efficient manner.
Ensure atomicity: Atomicity is simultaneous changes at all transactions. It is difficult in traditional file processing systems.
Concurrent access supervision: Especially in network environment it is necessary to supervise concurrent access to data. DBMS coordinate and control all sort of accession to data and their manipulation
Recovery from Failure: An Information System often handles several critical activities. In case of failure of hardware, software network, disk or other components of the computer system activities are abnormally terminated in the middle of its processing. Unless there is a mechanism to undo the damage and bring back the system to a previous consistent state in a logical manner, most IS will fail to provide proper service. DBMS approach provides the mechanism for the recovery from failure.
Reduced program maintenance: In a database environment, data are more independent of the application programs that use them. Within limits, we can change either the data or the application programs that use the data without necessitating a change in the other factor. As a result, program maintenance can be significantly reduced in a modern database environment.
Relational Database
The relational model was formally introduced by Dr. E. F. Codd in 1970 and has evolved since then, through a series of writings. The relational model represents data in the form of two-dimension tables.
- Data structure: In the relational model, a database is a collection of relational tables. The data structure is expresses in terms of relation, tuple, attribute and attribute value.
- Relation: A relational table is a flat file composed of a set of named columns and an arbitrary number of unnamed rows.
- Tuple: The rows of a relation are also called tuples.
- Attribute: A characteristic that identifies and describes a managed object.Simple: An attribute that cannot be broken down into smallerSimple: An attribute that cannot be broken down into smaller components e.g. Student: name
Complex: A collection of values of different type of attributes or a value that can be broken down into further attribute e.g. Student: Address
Derived attribute: An attribute that does not physically exist within the entity and is calculated via an algorithm from the value of other
attribute(s). Student: semester_fee =(tuition fee+ session charge+ exam fee - Discount)
Multi-valued attribute: An attribute that may take on more than one value for each entity instance. e.g. Book: Authorship (Multiple author for a title).
Constraints: The integrity constraints provide a logical basis for maintaining the validity of data values in the database. In other word, it is the restriction to the behavior of a variable. Codd's relational data model includes several constraints that are used to verify the validity of data in a database as well as to add meaningful structure to the data
Domain constraint: Each attribute takes values from a domain. The domain constraint refers to the definition of domain which means specifying the type, width, whether null values are allowed for that domain or not and values of compatible domains.
- Data type: Specify the supported data type for the column of the relation.
- Length: Specify the length of data.
- Unique: Prevents duplicates in non-primary keys and ensures that an index is created to enhance performance. Null values are allowed.
- Not null: Resists the user in case of skipping data entry of required attribute.
- Check: Specifies a validity rule for the data values in a column.
DATA STORAGE FORMAT ON DISK
A disk is divided into concentric circles called tracks where data is stored. A block is a collection of contiguous bytes of a single track. A block contains a number of records depending on the block size and record size and a file is a collection of records, which are mapped into disk blocks.
Track format
Records can be stored on disk in either a count-key format or a count-data format, as shown in Figures 10.5 and 10.6. The fundamental difference is that the count-key format includes a key that is external to the data record itself. This key is used by the operating system to access a particular record. We use the term record here in the general sense of a physical record, which is another name for a block. Both the count-data and the count-key formats can be described by the definitions that follow.
Each track has an index point, which is a special mark to identify the beginning of each track. Since the track is circular, it also identifies the end of the track.
The home address (HA) identifies the cylinder and the number of the read/write head that services the track, as well as the condition of the track (flag)- whether it is operative or defective. If the track is defective, an alternative track to be used is indicated. A two-byte cyclic check is included as a means of error detection in input/output operations.
Gaps (G) separate the different areas on the track. The length of the gap may vary with the device, the location of the gap, and the length of the preceding area. The gap that follows the index point is different in length from the gap that follows the home address, and the length of the gap that follows a record depends on the length of that record. The reason for this is to provide adequate time for required equipment functions that are necessary as the gap rotates past the read/write head. These functions may vary with the type of area that has just preceded the gap.
The address marker (A) is a two-byte segment supplied by the control unit (the hardware that controls the disk drive) as the record is written. It enables the control unit to locate the beginning of the record at a later time.
The count area is detailed in Figure 10.5. The flag field repeats the information about the track condition and adds information used by the control unit. The cylinder number, head number, and record number fields collectively provide a unique identification for the record. The key-length field is a one-byte field. It always contains a 0 for a record of the count-data format. The data-length field supplies two bytes, which specify the number of bytes in the data area of the record, excluding the cyclic check. The cyclic check provides two bytes for error detection.
Record Format
Physical records, or blocks, can be stored on tracks in any of the four formats.
Fixed length unblocked: There will one logical record for each physical record- the data that are actually stored in the record area of the track. For this we need to use a header based structure with additional space in records for pointers to other vacant fields. In this scheme the first record of a file is known as the file header which contains some information of the file, among which one is the address of the first available (free) record. And the first such record will store the address of the next available record in its pointer field and so on.
Fixed length blocked: More than one logical record will comprise each physical record. In this case the key area is typically assigned the key of the highest record of the block. Suppose that we have two succeeding blocks containing records 10,12,14, and 15,19,24, respectively. If the operating system is seeking logical record 15, the key for the first block will read 14, so record 15 cannot be in that block. The key for the next block will read 24. Since 24 is greater than 15, record 15 must be in that block. The entire block is then read into main memory where it is searched for record 15.
Variable length Record: The variable-length format, as the name implies, allows records to be of varying length. Variable length records arise in database in several ways:
- Storage of multiple record types in a file
- Record types that all allow variable lengths for one or more fields
- Record types allow repeating fields.
Because the record length is not uniform, a method of indicating where the record ends is required. This information is provided by the BL (block-length) and RL (record-length) areas. There are several techniques for implementing variable length records. Of them byte string representation and slotted page structure are prominent:
i) Byte string representation: The simple method of implementing variable length records is to attach a special end-of-record ( ) to the end of each record. An alternative version byte string representation stores the record length at the beginning of each record in stead of end-of-record symbol. it is easy but has some disadvantages:
a) it is not easy to reuse space occupied formerly by a deleted record. Though techniques exist to manager insertion and deletion, they lead to a large number fragmentation of disk storage that is wasted.
b) There is no space for record to grow longer. If a variable length record becomes longer, it must be moved.
ii) Slotted page structure: There is a header at the beginning of each block containing the following information:
i. The number of record entries in the header''
ii. The end of free space in the block
iii. An array whose entries contain the location and size of each record.
The actual records are allocated contiguously in the block, starting from the end of the block. The free space in the block in contiguous, between the final entity in the header array and the first record. If the record is inserted, space is allocated for it at the end of the free space and an entity containing the size and location is added to the header.
Entries Free Space
Slotted Page structure
Different types of File Organization
Heap or Pile
Sequential
Indexed Sequential
B - Tree Indexing
Heap or Pile
This is the simplest form of representation in which one record is piled or stacked one after the other. Insertion is very simple. Records are added at the end of the file. Delete is done by marking a special field in the record. Search requires substantial time since every record will be searched. For updation, the steps are - find old record, invalidate the record, add new record at the end. All operations except insertion are expensive.
Sequential file
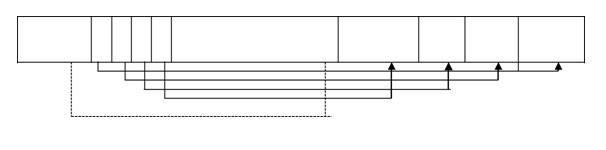
In a sequential file records are stored sequentially based on some attribute(s) value, usually the primary key. Each record has a pointer and it points the next record in primary key order. Fig. 11.10 shows sequential arrangement of the file of a book table Insertion and deletion are performed as discussed in section 11.3.)

In sequential organization it is difficult to maintain physical sequential order as more records are inserted or deleted. This is because it is costly to move many records as a result of single insertion or deletion. Insertion becomes quite complex if we want to maintain records in the same block as its predecessor and successor. For this during insertion we have to find out the record which comes before that new record and then search for free space within the same block
Indexed-sequential file
In order to access records fast we often use an indexed-sequential file. Here an index structure is used which is associated with a particular search key. There can be multiple indices depending on the search key. The main index (whose search key is based on the primary key) is called the primary index. Other indices are called secondary indices. Indexing can be of two types dense and sparse as explained below.
Dense index - Here one index record of the index file appears for every search-key value in the data file. The index record contains the search-key value and a pointer to the first record/block in the sequential file with the same search key value. The index file is ordered according to the search key.
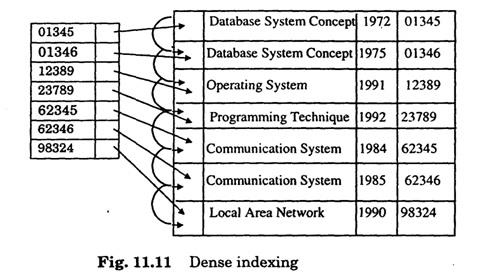
Sparse index - Here the index file will contain some of the records instead of all the records. To find a record, we search the index record with the largest search key value that is less than or equal to the search key value which we are looking for. We start at that point and continue sequentially in the data file to find the desired record.
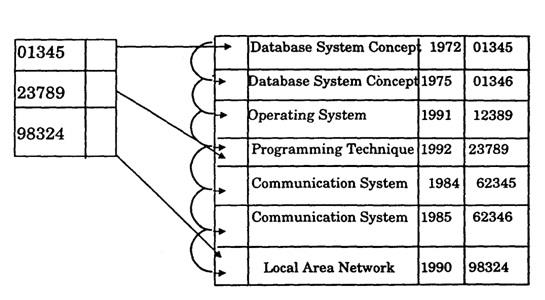
Multilevel Index
The index file itself may be too large even if we use sparse indexing. We can use another level of indexing for index files to increase the searching speed. This technique is known as multilevel sparse indexing. Fig 11.13 is shows the multilevel spare indexing structure.
Secondary Index
We often want to search records based on attributes other than the primary- key. For this we create an index structure on those attributes. Index on non- prime attributes is known as a secondary index. Assume that in the book file acc_no is the primary key and we wish to retrieve records using the attribute title. In the index file records are arranged depending on title but in the data file records are arranged on acc To link records in the data block we have to use another set of pointers as shown in Fig. 11.14.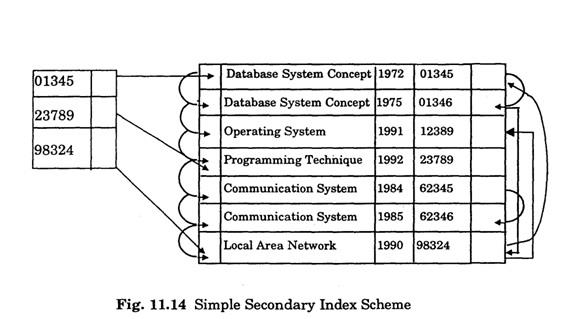
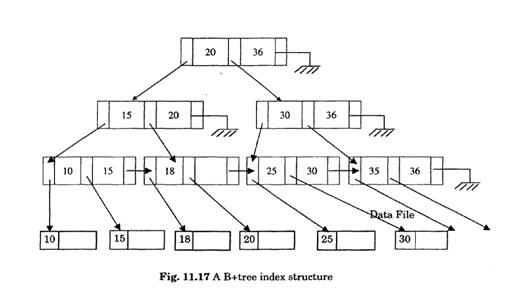
B -Tree Index Files
The performance of an indexed-sequential file degrades as the file grows. The B -Tree index file is a balanced index tree which help us to insert, delete and update data efficiently. (A tree is balanced if every path from the root of the tree to a leaf of the tree is nearly of the same length. ) Each node of the index tree structure will be the size of a block. Each record in a node corresponds to a key attribute and if there are k records then we have k÷1 pointers
p1, p2, p3 are 3 pointers. p1 points to record with acc_no 5272, p points to nodes with ace_no> 5272 and 5384 and p3 points to nodes with acc_no> 5384. Records in a node are stored in sorted order. The top most level of a tree is known as root and nodes of lowest level are known as leaf nodes. The pointer of leaf node directly points to actual data records in the data file. An index tree structure is shown in Fig. 11.17.
DBMS - Relational Database Expert Service 24/7 - Get Assignment Help at your door steps!
We help students, scholars and professionals with their DBMS projects, Relational database projects, database homework and assessments writing. We provide best solutions to DBMS assignments and homework. Our experts are highly qualified and talented and they provide efficient solutions to your university work projects and classroom assignments. They prepare each assignment and project from scratch and provide best working solutions as per the guidelines of university. We offer DBMS assignment help, database assignment help, DBMS - Relational database project development service and classroom assessments writing service.
Why we for DBMS - Relational Database Expert Service?
- Highly qualified and experienced experts - long working experience in real time working environments.
- Best quality work from scratch - no plagiarism
- Affordable price for each Database project and assignment as per student's point of view.
- We never miss your deadlines.
- Best writing skills and demonstration of DBMS - Relational Database solutions
- Step by step work to better understand the solutions
- Unlimited revisions till end of your satisfaction